
Any links to online stores should be assumed to be affiliates. The company or PR agency provides all or most review samples. They have no control over my content, and I provide my honest opinion.
Following up on my previous post about identifying websites that scrape content and finding out their IP and hosting provider, this article covers stopping those websites from scaping your content.
As a reminder, the negative impact of scrapers is up for debate. In theory, Google should ignore these, and if you do a site search of a scraper (site:scraperdoman.com), you will typically see very few pages indexed.
Therefore, it could be argued that spending hours every month or two filling DMCA requests is a waste of time.
On the flip side, some people have theorised that one of the issues websites have experienced with the Google Helpful Content Update is related to poor backlinks profiles partly caused by scrapers. But, of course, the official word from Google has always been that these don’t matter, they just get ignored.
Submitting DMCA / Copyright Takedown Notices
If you have successfully identified the hosting provider of a website scraping your content, then the best bet is to submit a DMCA request to their host.
Some hosts ignore them, but most don’t. From my experience, many scrapers don’t respond to the DMCA request, and the website gets taken down, which always gives me a bit of satisfaction.
Many will remove your content and stop scraping. Some will just remove the content you listed and continue scraping.
First of all, search for the hosting provider + DMCA, and you will normally find the official policy on these requests. Most of the time, you just email abuse@hostingproviderdomain.com.
You will then need to get a list of the posts that have been scraped and the corresponding original URLs. I typically only get a few URLs, just enough to prove they are scraping.
You will then want to place all the relevant information into a DMCA request. You can download a sample DMCA request here, or search online for many other examples.
Within the request, I typically explain how they can easily identify the content as mine, such as watermarks, hot-linked images, or references and links to my website.
Submitting DMCA Takedown Notices to Google
You can have content removed from Google by using the Report Content on Google service.
I have stopped doing this in most scenarios because you only remove content that’s on Google. It doesn’t stop the site from scraping content, and no matter how many requests you make against a single website, Google will continue to index/rank it.
How to Block a Website from Scraping Content
If you have identified the IP address but have had no look at the DMCA takedown, you can try and stop a site from scraping your content by blocking its IP.
This is another thing that’s hit or miss. A lot of scrapers will use a different URL than their host to scrape content and often will use proxies to switch the IP. But, many don’t, and this can be effective.
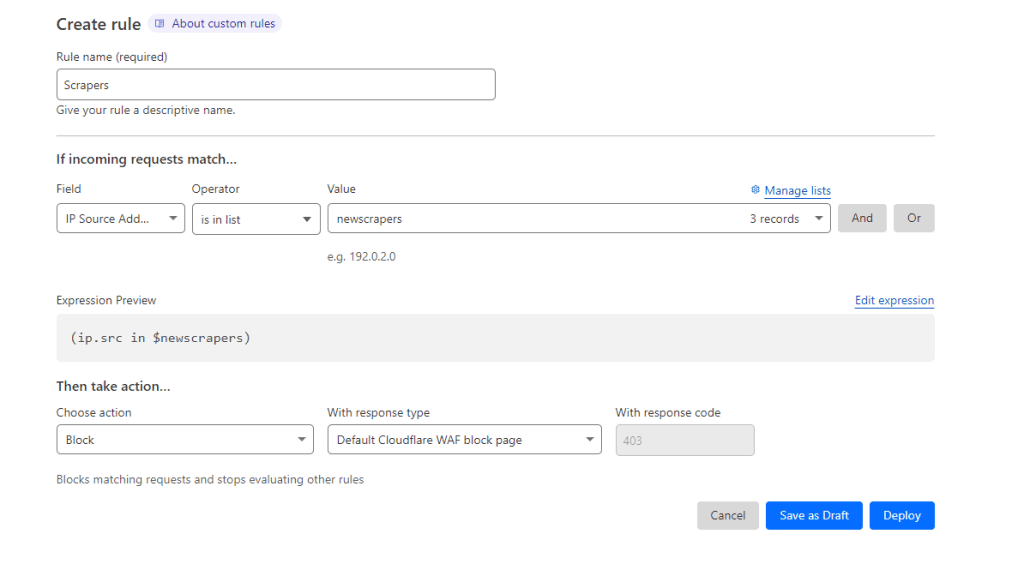
I recommend using Cloudflare for your website and using Cloudflare, you can create lists of IP addresses by going to Manage Account > Configurations > Lists.
Then, under the domain settings, go to Security > WAF and create a new rule.
I set the If incoming requests match the IP source is in list then the name of the list.
Then, I select Block for the action and Default Cloudflare WAF block page.
How to Block a Website from Hotlinking Images
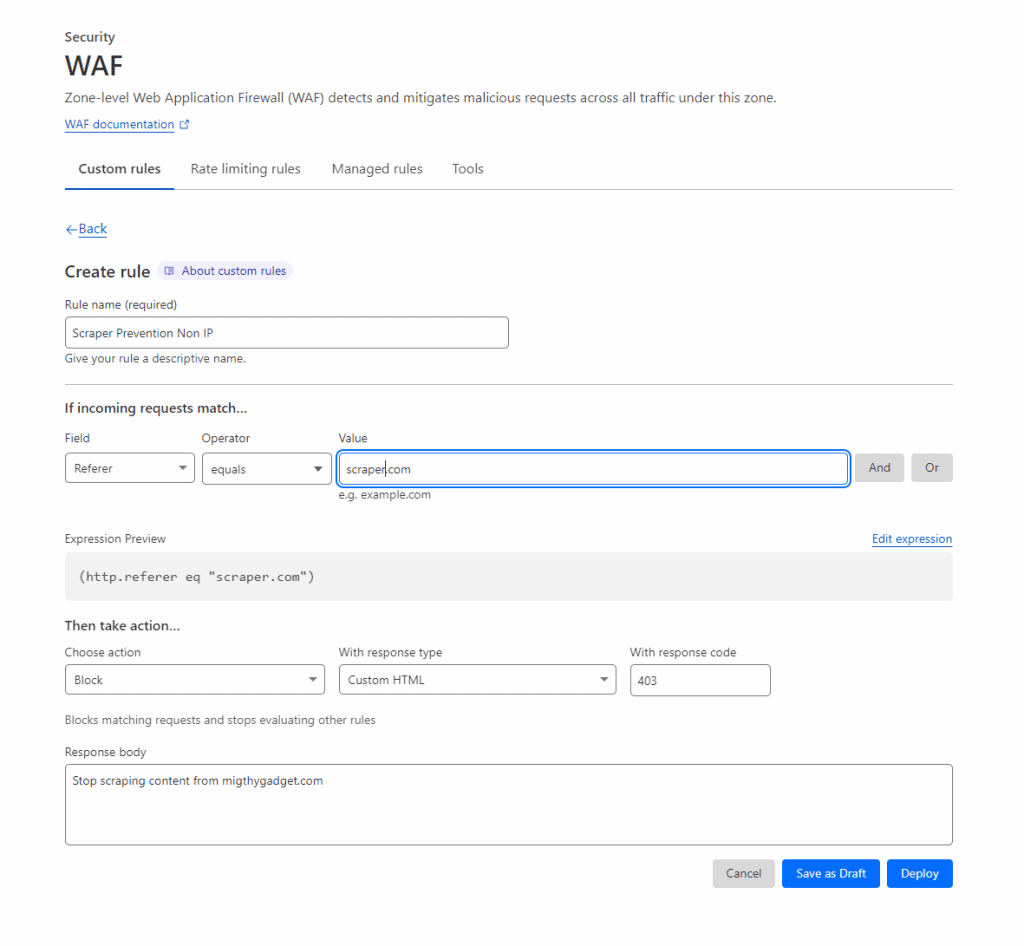
Cloudflare has a built-in hotlinking prevention tool, which can be effective, but I find it can sometimes cause issues with images displayed on valid third-party websites such as news aggregators like Feedly.
Alternatively, you can manually create your own rules via the Web Application Firewall (WAF) again, or the rules function.
Blocking image hotlinking doesn’t make a great deal of difference, but if the scraper is successfully ranking content, it should hopefully ruin the user experience of anyone viewing that content.
Part 1 of this guide can be found here.
Originally published on migthygadget.com
I am James, a UK-based tech enthusiast and the Editor and Owner of Mighty Gadget, which I’ve proudly run since 2007. Passionate about all things technology, my expertise spans from computers and networking to mobile, wearables, and smart home devices.
As a fitness fanatic who loves running and cycling, I also have a keen interest in fitness-related technology, and I take every opportunity to cover this niche on my blog. My diverse interests allow me to bring a unique perspective to tech blogging, merging lifestyle, fitness, and the latest tech trends.
In my academic pursuits, I earned a BSc in Information Systems Design from UCLAN, before advancing my learning with a Master’s Degree in Computing. This advanced study also included Cisco CCNA accreditation, further demonstrating my commitment to understanding and staying ahead of the technology curve.
I’m proud to share that Vuelio has consistently ranked Mighty Gadget as one of the top technology blogs in the UK. With my dedication to technology and drive to share my insights, I aim to continue providing my readers with engaging and informative content.



![UREVO Kardio T1 Exercise Bike Review – A cheap Zwift compatible spin bike [Model URSB002]](https://mightygadget.com/wp-content/uploads/2022/01/UREVO-Kardio-T1-Exercise-Bike-Review-768x475.jpg)

