Any links to online stores should be assumed to be affiliates. The company or PR agency provides all or most review samples. They have no control over my content, and I provide my honest opinion.
If you run a website that publishes a lot of content, then you will almost certainly experience other websites scraping your content and trying to publish it as their own.
This can have a negative impact on your rankings within Google or other search engines. In the past, I have had issues with a scraper getting their content indexed before mine and then outranking me.
Some scrapers are also worse than others. A common problem I have witnessed is a site will scrape all your content and then remove any internal links you may have used, sometimes removing all links (such as external affiliate links), and often, they will do a poor job of word replacement in an attempt to make it unique.
A lot of the time, but not all, they will add a source link at the bottom as if this justifies the scraping as “fair use”.
In all the cases I have experienced when a website scrapes the content, they may host the featured image on their own website/CDN but will always hotlink any other images within your content, which, in theory, will cause more data usage on your server and increase costs or slow your server down.
In my case, I have had someone on Fiverr listing gigs for automated tech news websites and selling them for £60. You can probably guess that they achieve this through scraping content from other websites, and mine is one of those.
What impact scraping has on a website is unknown. In theory, Google should be intelligent enough to ignore it as it can tell that the content is not unique. Many of these sites have thousands of pages, yet Google only shows a few hundred indexed.
Again, Google should ignore them, but these sites will often create an ugly backlink profile, which could potentially have a negative effect on a website.
Unfortunately, many websites have had a significant dip in traffic and rankings through the recent Helpful Content Update and multiple other Google updates recently.
It has, therefore, become increasingly important to try and make sure Google sees the original content and views the original site as trustworthy and authoritative. Having the content republished on dozens of websites is not going to help that.
One thing to be aware of is that you should perhaps consider if the time invested in taking down scrapers is worth it. Constantly submitting DMCA requests is time-consuming, and in theory, Google should be ignoring these sites in the first place.
How to Identify Websites Scraping Content
The first problem is identifying the sites scraping your content. In the worst case scenarios, the website that’s scraping content will rank for the same terms your content ranks for, or even worse, outrank you.
Back in 2019, I had an issue with Google indexing my site quickly, and the scraper ranked the content first with me nowhere. Even though the content had links back to my site and hot-linked images, Google failed to identify it as duplicate content.
Google Search
So, any important content you review can be worth searching for easy-to-find terms. For me, that’s easy, I can search for things like TP-Link Tapo P110M Smart Plug Review.
Ahrefs Webmaster Tools
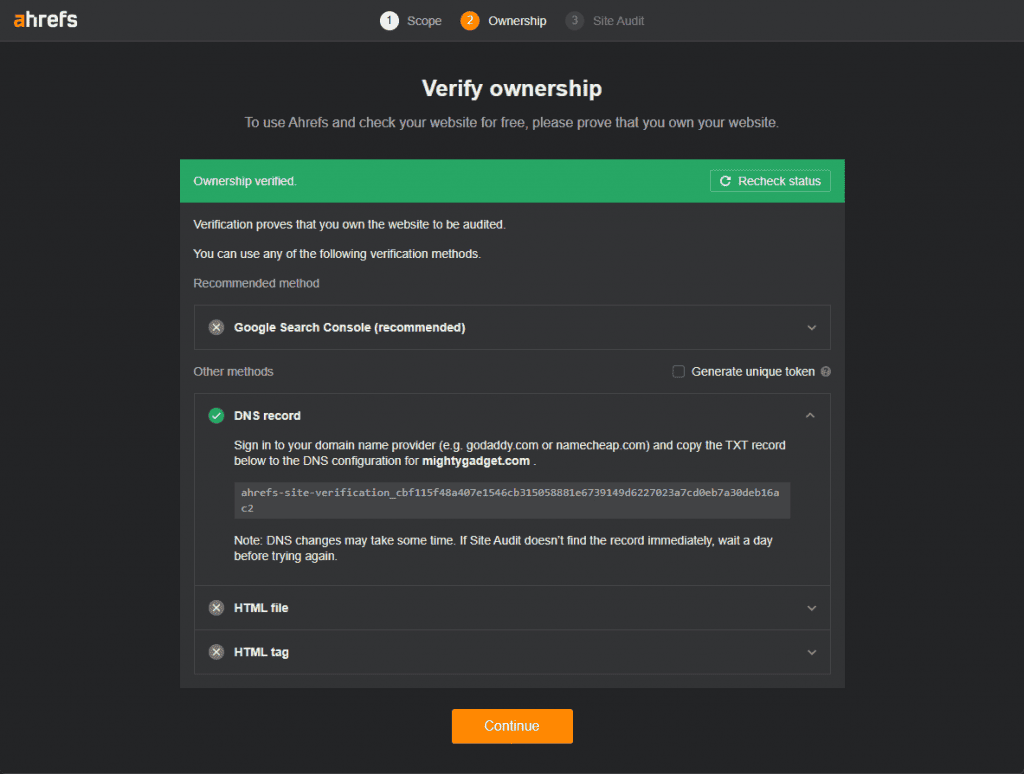
The other main method I use is Ahrefs. It is a painfully expensive service, which is often too expensive for independent bloggers to justify the cost. However, you should be able to get basic access to some of the most useful data free of charge using the free Ahrefs Webmaster Tools (AWT).
You must confirm ownership of the website via Google Search Console or manually via a DNS record, HTML file or HTML tag.
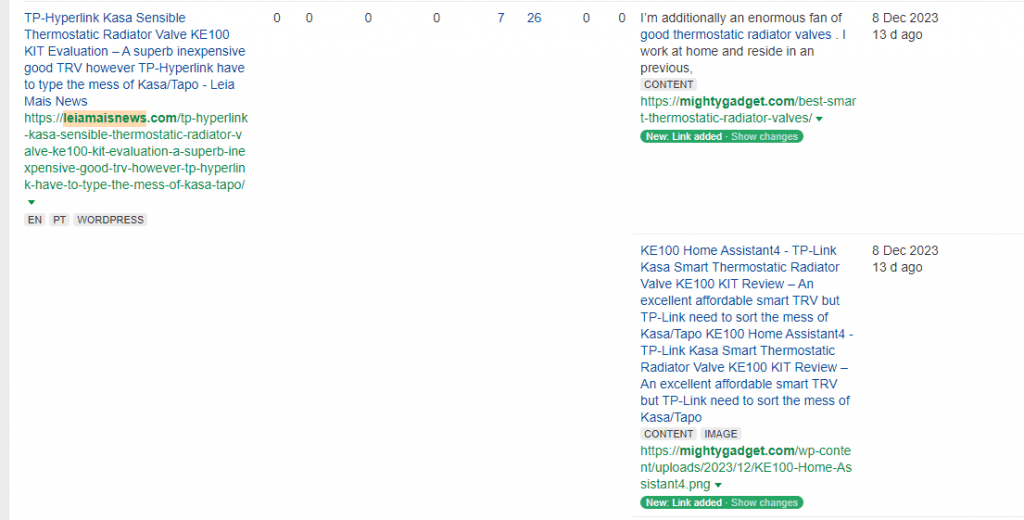
Once you have access to Ahrefs, you should be able to view all the backlinks your website has. I will normally sort the content by first seeing as you want to identify people actively scraping your content.
Sometimes, the backlink will be identified as an image; otherwise, you will need to hope they have included a link back to you at some point in the article.
How to avoid links being removed

Many websites will remove links that go back to the host website, which makes it harder to identify who the scraper is. The easiest workaround for this, I have come up with, is to use a URL shortener and internally link to your own content via the URL shortener. You should then start seeing links from scrapers as the URL shortener 301 redirects back to your website.
How to Find the IP or Host of a Website Scraping Content
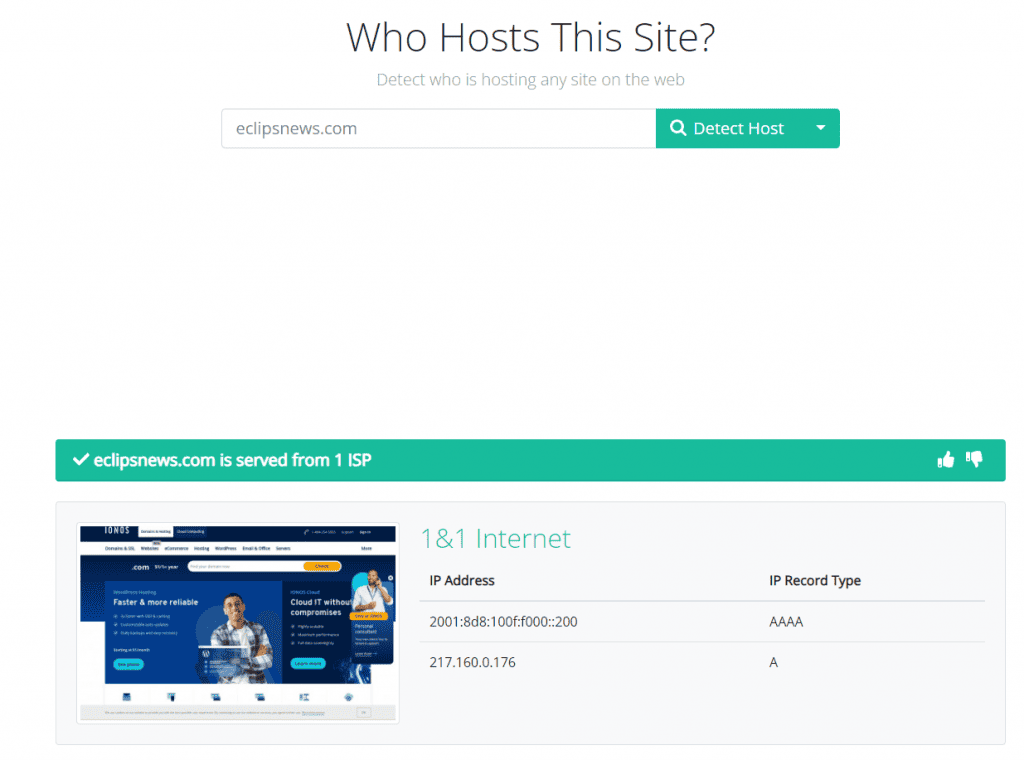
Identifying the website is only a small step to fixing the problem. Most scrapers either don’t have a working contact form or don’t bother to reply to take-down requests.
You will, therefore, need to find the IP address and/or hosting provider and submit a DMCA request to them.
The first step I took was to use who-hosts-this.com, which is the quickest method I have tried.
If you are lucky, you will be provided with the correct host, and you can move on to the DMCA process.
Often, many websites registered with Cloudflare and who-hosts-this.com identify Cloudflare as the host.
If this happens, you will need to use the Cloudflare report abuse feature. You will need to select DMCA, fill out your details, and provide examples of the original work and infringing URL.
They should quickly reply, providing you with the hosting provider and the contact email for DMCA requests.
An alternative option I tried in the past is to look at any pingbacks within WordPress. I have these disabled, so it is not much use to me anymore.
Other alternative options include:
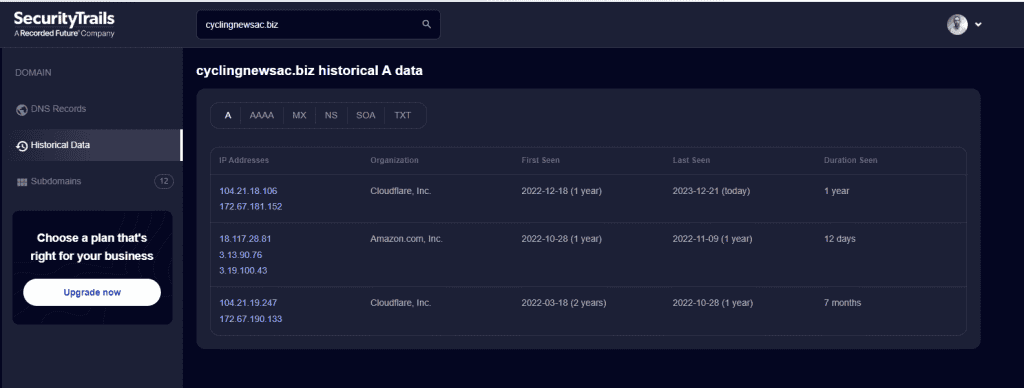
SecurityTrails: If you sign up for an account, you can see historical DNS records, and this can often expose what the server and IP were prior to moving to Cloudflare
PHP to expose the scraper IP: This is not an ideal option, but I previously had success with using a WordPress plugin such as WPCode to get the client IP and output it at the bottom of a post. When a scraper copies the content, it copies the IP. For Cloudflare, it would normally show the CloudFlare IP, but
The code I used was:
$ip = getenv("HTTP_CLIENT_IP")?:
getenv("HTTP_X_FORWARDED_FOR")?:
getenv("HTTP_X_FORWARDED")?:
getenv("HTTP_FORWARDED_FOR")?:
getenv("HTTP_FORWARDED")?:
getenv("REMOTE_ADDR");Then, you can output $ip however you like. Recently, this hasn’t appeared to work, as I just get the IP for sites like Yandex.
There is also the mod_cloudflare for Apache, which is the official module that allows you to capture real IP addresses. The Cloudflare documentation states this is no longer updated, but the mod_remoteip works with operating systems such as Ubuntu Server 18.04 and Debian 9 Stretch. CloudFlare has a guide on restoring the original visitor IP.
In the next part of this guide, I will cover submitting DMCA copyright takedown notices to hosts, submitting DMCA requests to good, and how to block sites from scaping content and hotlinking images.
Originally published on migthygadget.com
I am James, a UK-based tech enthusiast and the Editor and Owner of Mighty Gadget, which I’ve proudly run since 2007. Passionate about all things technology, my expertise spans from computers and networking to mobile, wearables, and smart home devices.
As a fitness fanatic who loves running and cycling, I also have a keen interest in fitness-related technology, and I take every opportunity to cover this niche on my blog. My diverse interests allow me to bring a unique perspective to tech blogging, merging lifestyle, fitness, and the latest tech trends.
In my academic pursuits, I earned a BSc in Information Systems Design from UCLAN, before advancing my learning with a Master’s Degree in Computing. This advanced study also included Cisco CCNA accreditation, further demonstrating my commitment to understanding and staying ahead of the technology curve.
I’m proud to share that Vuelio has consistently ranked Mighty Gadget as one of the top technology blogs in the UK. With my dedication to technology and drive to share my insights, I aim to continue providing my readers with engaging and informative content.